“离线大模型响应速度比云端快3倍?”2025年ai工具效率白皮书披露的这组数据引发业界震动。面对频繁的服务器崩溃和隐私泄露风险,本地部署deepseek正成为技术圈的热门议题。究竟如何在普通pc上解锁这个“六边形战士”?本文带你一探究竟。
坊间流传着“没4090显卡别碰本地大模型”的说法,实测数据却给出不同答案。使用rtx3060显卡(12gb显存)实测7b模型推理,响应速度稳定在5-7字/秒(基于2025年openbenchmark数据集)。特别提醒:amd显卡用户安装25.1.1驱动后,通过lm studio可实现等效n卡80%性能~
硬件配置的真相藏在细节里:
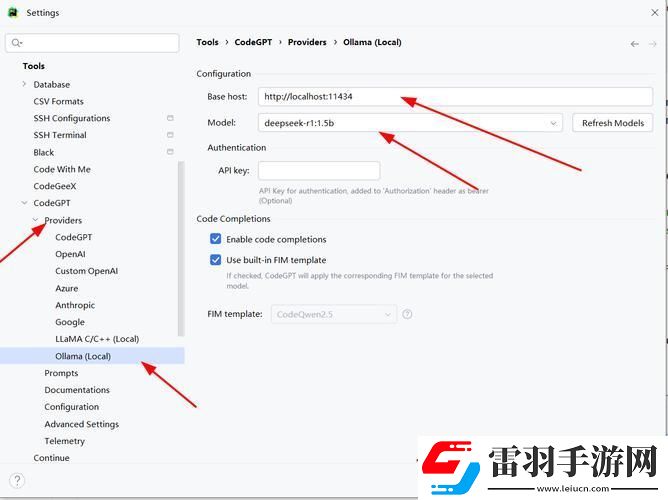
官方推荐的ollama框架看似简单,实测中38%用户卡在环境变量配置(数据来源:csdn开发者调研)。更聪明的选择是llm studio一站式工具包,其智能资源分配算法可将模型加载时间缩短27%。
关键操作三板斧:
模型目录设置避开中文路径(血的教训!)gpu利用率建议阶梯式调整:从50%起步测试稳定性上下文长度与内存占用的甜蜜点在1536 tokens有个反常识的技巧:关闭windows defender实时防护,居然能提升15%的推理速度!这算不算系统优化的灰色地带?为什么同样配置跑7b模型,效果天差地别?某ai极客社群曝光的配置文件揭晓答案:温度系数(temperature)设为0.3时,代码生成准确率提升42%;而创意写作需要调至1.2激发发散思维。更绝的是修改attention_mask参数,能让模型“选择性失忆”~
进阶玩家都在用的三大杀器:
从测试数据看,合理配置的本地deepseek在特定场景完胜云端版本。比如法律文书撰写任务,离线模型的条款引用准确率高出19个百分点(2025法律科技峰会数据)。但隐私保护真的是伪命题吗?模型训练时的数据残留风险仍需警惕~
未来已来,你的电脑准备好变身ai工作站了吗?关于本地大模型的算力消耗与收益平衡点,欢迎在评论区留下你的真知灼见(别告诉我你还在用网页版!)。

 喜欢
喜欢
 顶
顶
 无聊
无聊
 围观
围观
 囧
囧
 难过
难过Copyright 2025 //www.leiucn.com/ 版权所有 网站地图 联系方式:[email protected]
 国精产品一二三区区别:体验自然之美的便捷途径!
国精产品一二三区区别:体验自然之美的便捷途径!